 我们与乌克兰的朋友和同事站在一起。要支持乌克兰度过难关,
我们与乌克兰的朋友和同事站在一起。要支持乌克兰度过难关,架构
另请参阅
术语
Jaeger 使用受 OpenTracing 规范 启发的 数据模型 表示跟踪数据。此数据模型 在逻辑上非常类似于 OpenTelemetry 跟踪 ,只是名称略有不同。
| Jaeger | OpenTelemetry | 注释 |
|---|---|---|
| 标签 | 属性 | 两者都支持类型化值,但 Jaeger 不支持嵌套标签。 |
| 跨度日志 | 跨度事件 | 以结构化形式记录在跨度上的时间点事件。 |
| 跨度引用 | 跨度链接 | Jaeger 的跨度引用具有必需的类型(child-of 或 follows-from)并且始终引用前驱跨度;OpenTelemetry 的跨度链接没有类型,但允许属性。 |
| 进程 | 资源 | 描述产生遥测数据的实体的结构。 |
跨度
一个 跨度 代表一个逻辑工作单元,具有操作名称、操作开始时间和持续时间。跨度可以嵌套和排序以模拟因果关系。
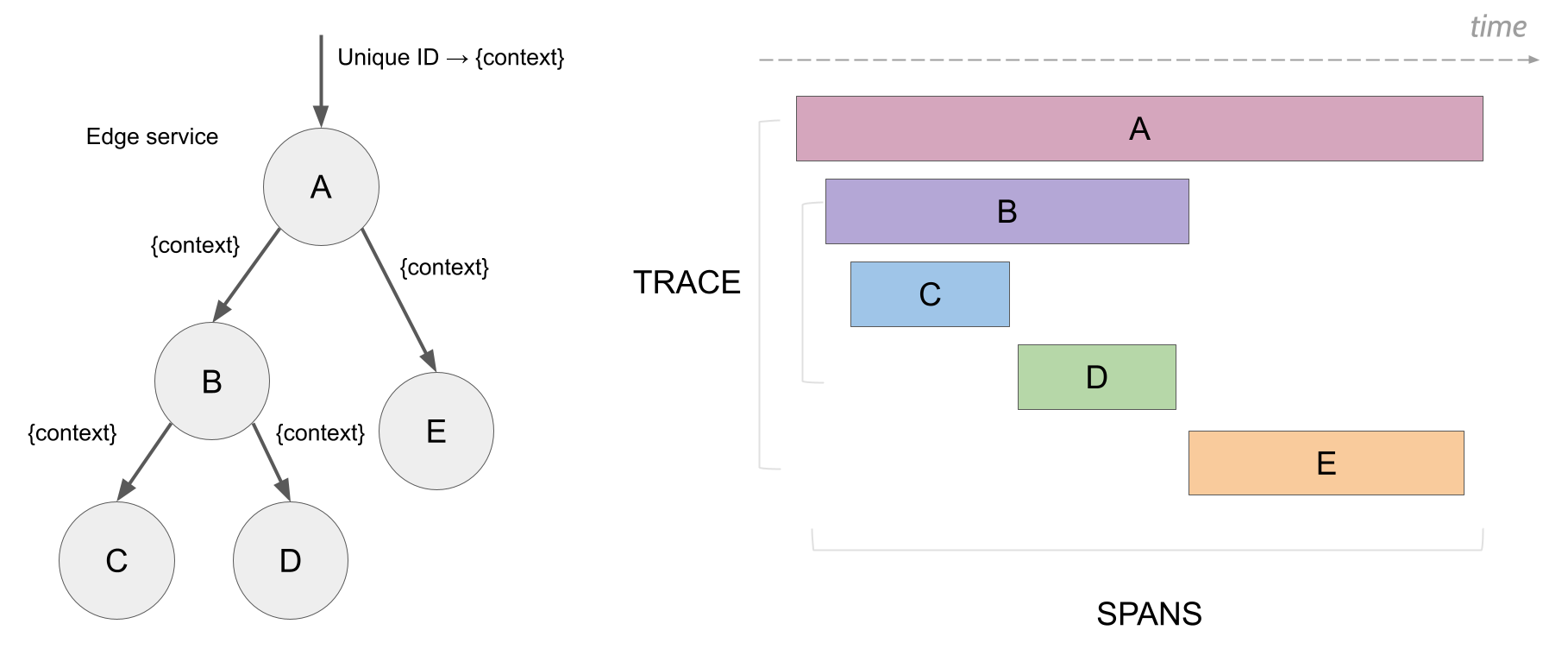
跟踪
一个 跟踪 代表通过系统的数据或执行路径。可以将其视为跨度的有向无环图。
行李
行李 是可以附加到分布式上下文并由跟踪 SDK 传播的任意用户定义的元数据(键值对)。有关更多信息,请参见 W3C 行李 。
架构
Jaeger 可以部署为 一体化 二进制文件,其中所有 Jaeger 后端组件都在单个进程中运行,也可以部署为可扩展的分布式系统。下面讨论了两种主要的部署选项。
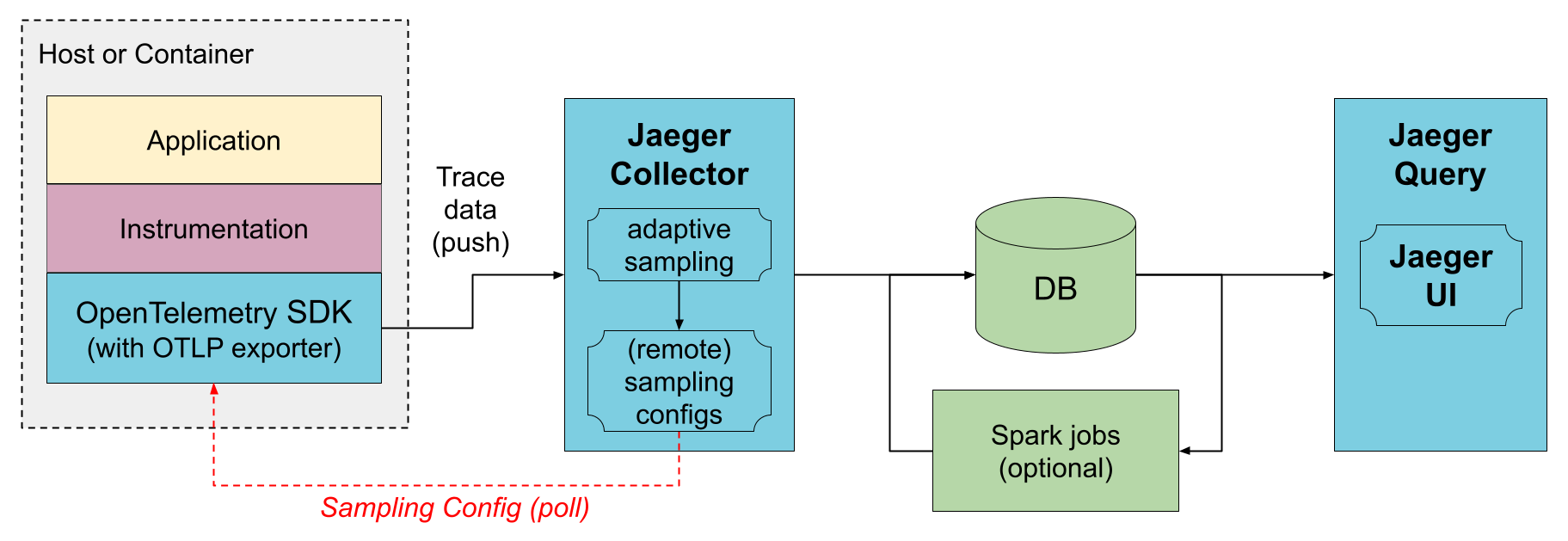
直接到存储
在此部署中,收集器从跟踪的应用程序接收数据并将其直接写入存储。存储必须能够处理平均流量和峰值流量。收集器使用内存中队列来平滑短期流量峰值,但如果存储跟不上,持续的流量峰值可能会导致数据丢失。
收集器能够将采样配置集中地提供给 SDK,这称为 远程采样模式。它们还可以启用自动采样配置计算,这称为 自适应采样。
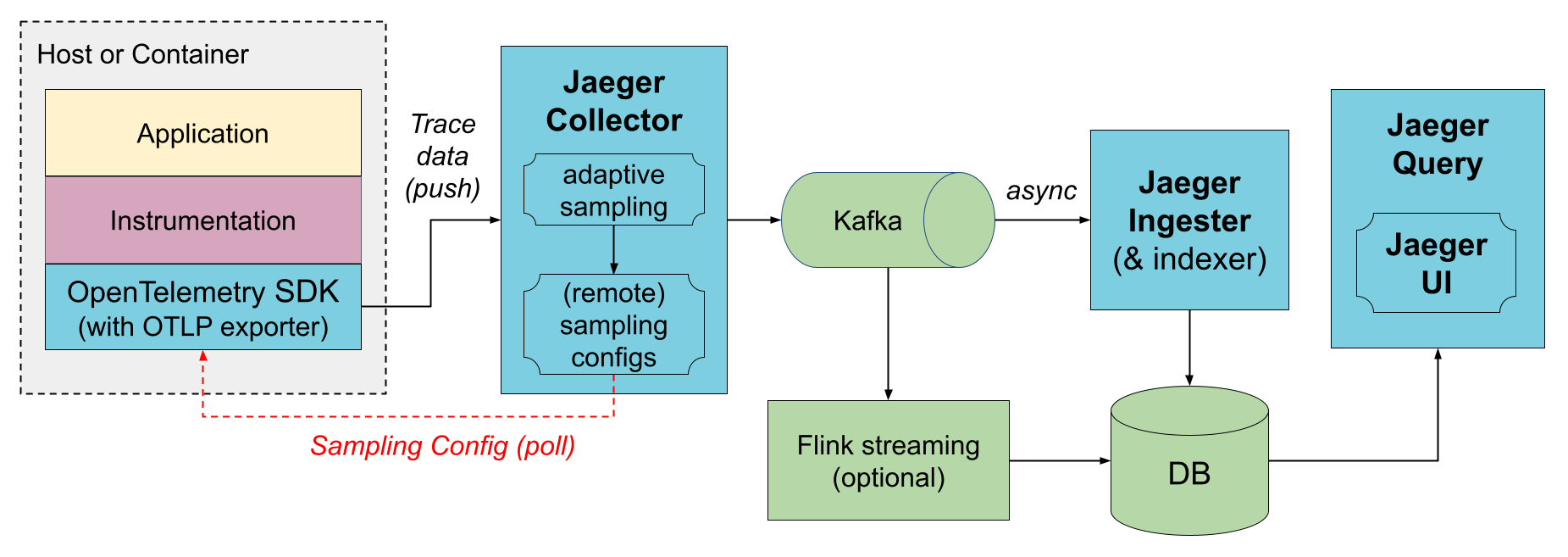
通过 Kafka
为了防止收集器和存储之间的数据丢失,可以使用 Kafka 作为中间持久队列。需要部署一个额外的组件 jaeger-ingester 来从 Kafka 读取数据并保存到数据库。可以部署多个 jaeger-ingester 来扩展摄取;它们将自动在它们之间划分负载。
使用 OpenTelemetry 收集器
您 不需要使用 OpenTelemetry 收集器,因为 jaeger-collector 可以直接从 OpenTelemetry SDK(使用 OTLP 导出器)接收 OpenTelemetry 数据。但是,如果您已经使用 OpenTelemetry 收集器(例如,用于收集其他类型的遥测数据或用于预处理/丰富跟踪数据),则可以将其 放置在 SDK 和 jaeger-collector 之间。OpenTelemetry 收集器可以作为应用程序 sidecar、主机代理/守护程序或中央集群运行。
OpenTelemetry 收集器支持 Jaeger 的远程采样协议,可以从配置文件直接提供静态配置,也可以将请求代理到 Jaeger 后端(例如,当使用自适应采样时)。
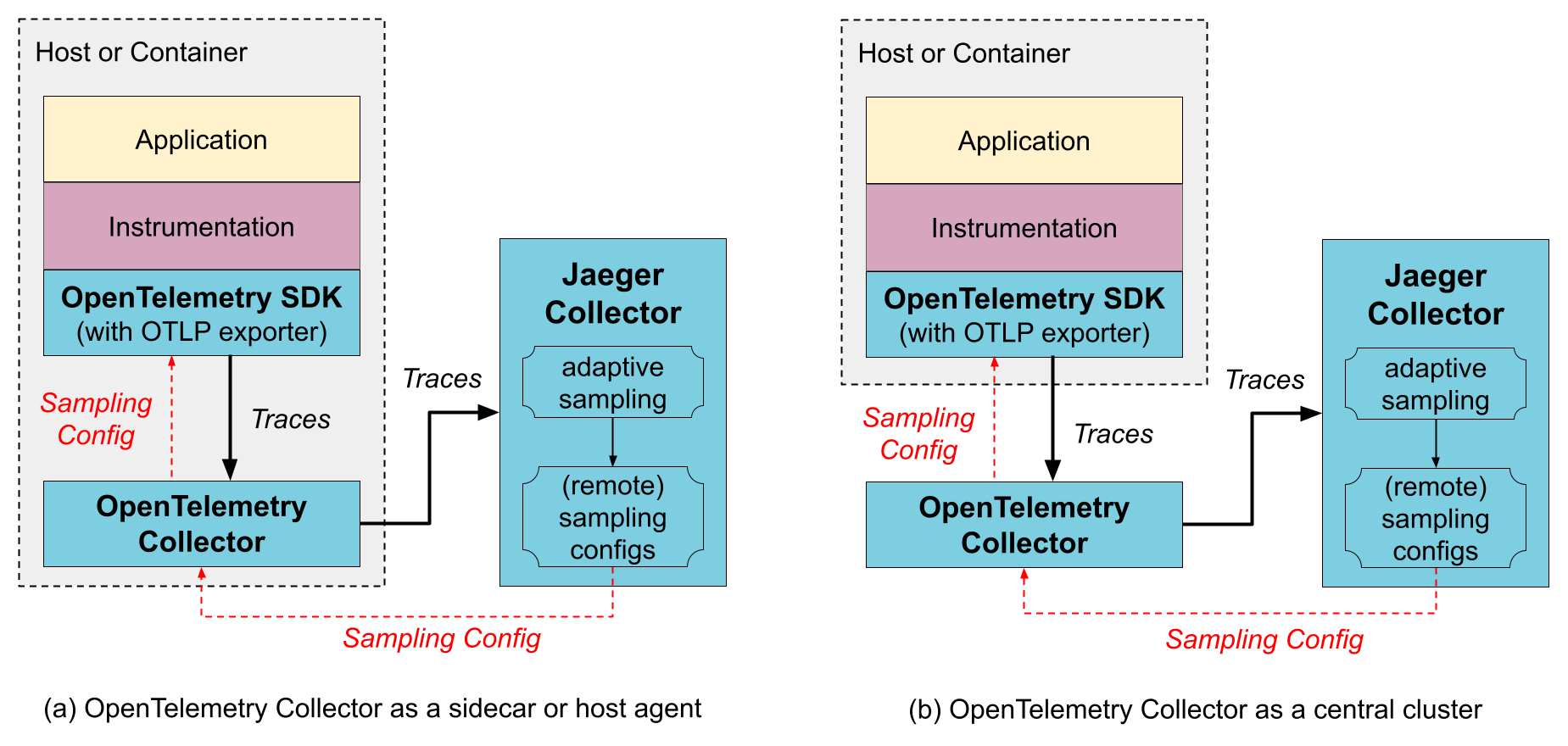
OpenTelemetry 收集器作为 sidecar/主机代理
优势
- SDK 配置简化,因为跟踪导出端点和采样配置端点都可以指向本地主机,而无需担心远程发现这些服务运行的位置。
- 收集器可以通过添加环境信息(如 k8s pod 名称)来提供数据丰富。
- 用于数据丰富的资源使用可以分布到所有应用程序主机上。
缺点
- 数据编组/解组的额外层。
OpenTelemetry 收集器作为远程集群
优势
- 分片功能,例如,当使用 基于尾部的采样 。
缺点
- 数据编组/解组的额外层。
组件
本节详细介绍 Jaeger 的组成部分以及它们之间的关系。它按您的应用程序中的跨度与它们交互的顺序排列。
跟踪 SDK
为了生成跟踪数据,应用程序必须进行 instrumentation(添加追踪代码)。一个 instrumented 的应用程序在接收到新的请求时创建 spans,并将上下文信息(跟踪 ID、span ID 和 baggage)附加到传出的请求。只有 ID 和 baggage 会随着请求传播;所有其他 profiling 数据,如操作名称、计时、标签和日志,都不会传播。相反,它们会异步地在后台导出到 Jaeger 后端,并进行处理。
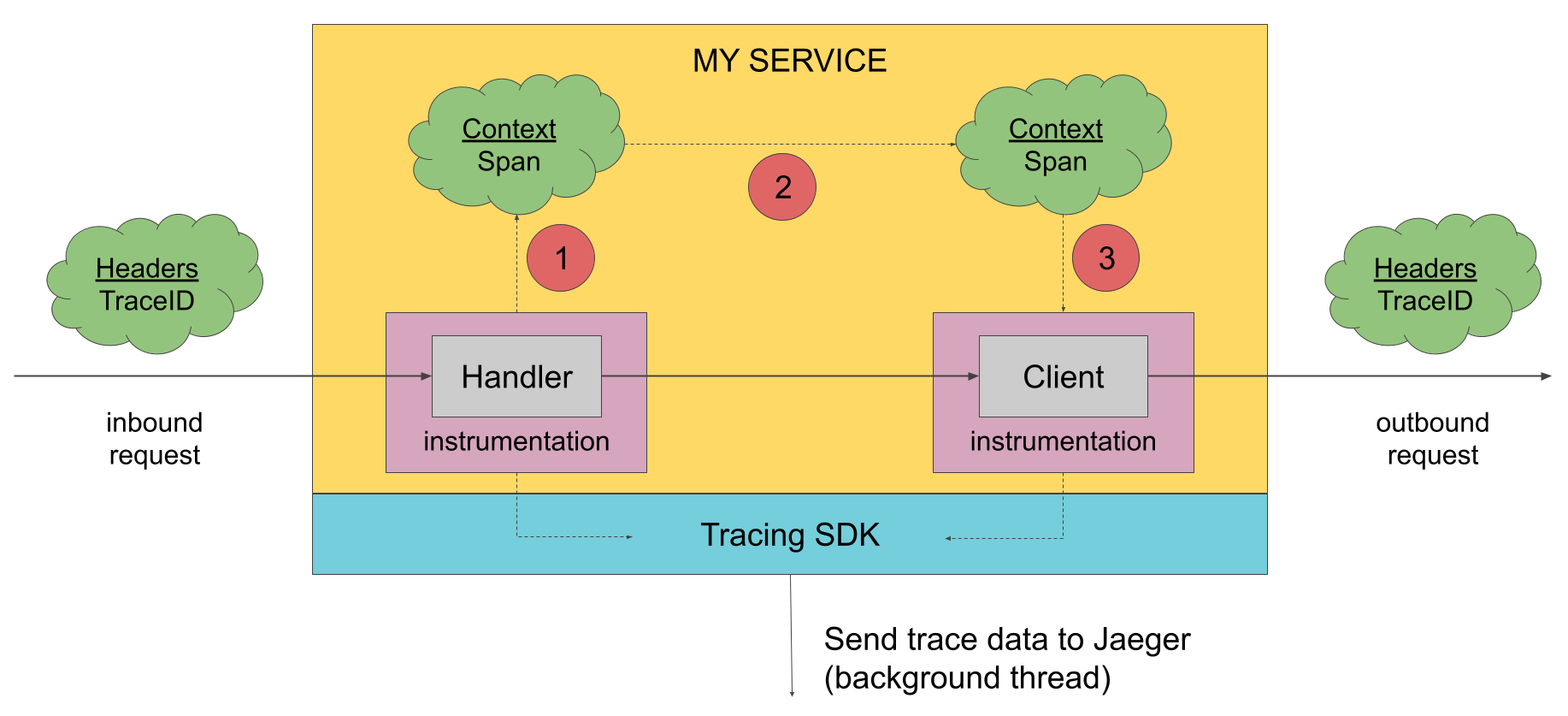
有许多方法可以为应用程序添加 instrumentation
- 手动,直接使用跟踪 API,
- 依赖于为各种现有开源框架创建的 instrumentation,
- 自动,通过字节码操作、monkey-patching、eBPF 等技术。
instrumentation 通常不应依赖于特定的跟踪 SDK,而应该依赖于抽象的跟踪 API,例如 OpenTelemetry API。跟踪 SDK 实现跟踪 API,并负责数据导出。
instrumentation 设计为在生产环境中始终处于开启状态。为了最小化开销,SDK 采用各种采样策略。当采样一个跟踪时,会捕获 profiling span 数据并传输到 Jaeger 后端。当不采样一个跟踪时,不会收集任何 profiling 数据,对跟踪 API 的调用会短路以产生最小的开销。有关更多信息,请参考 采样 页面。
Agent
jaeger-agent 是一个网络守护进程,它监听通过 UDP 发送的 spans,并将它们进行批处理并发送到 collector。它被设计为部署到所有主机作为基础设施组件。agent 将 collector 的路由和发现抽象出来,使其与客户端无关。jaeger-agent **不是** 必需组件。
Collector
jaeger-collector 接收跟踪,运行它们通过处理管道进行验证和清理/丰富,并将它们存储在存储后端。Jaeger 内置支持多种存储后端(参见 部署 ),以及用于实现自定义存储插件的可扩展插件框架。
Query
jaeger-query 是一个服务,它公开 API 用于从存储中检索跟踪,并托管 Web UI 用于搜索和分析跟踪。
Ingester
jaeger-ingester 是一个服务,它从 Kafka 读取跟踪并将其写入存储后端。实际上,它是一个简化的 Jaeger collector 版本,只支持 Kafka 作为唯一的输入协议。