 我们与乌克兰的朋友和同事站在一起。如需支持乌克兰,请
我们与乌克兰的朋友和同事站在一起。如需支持乌克兰,请服务性能监控 (SPM)
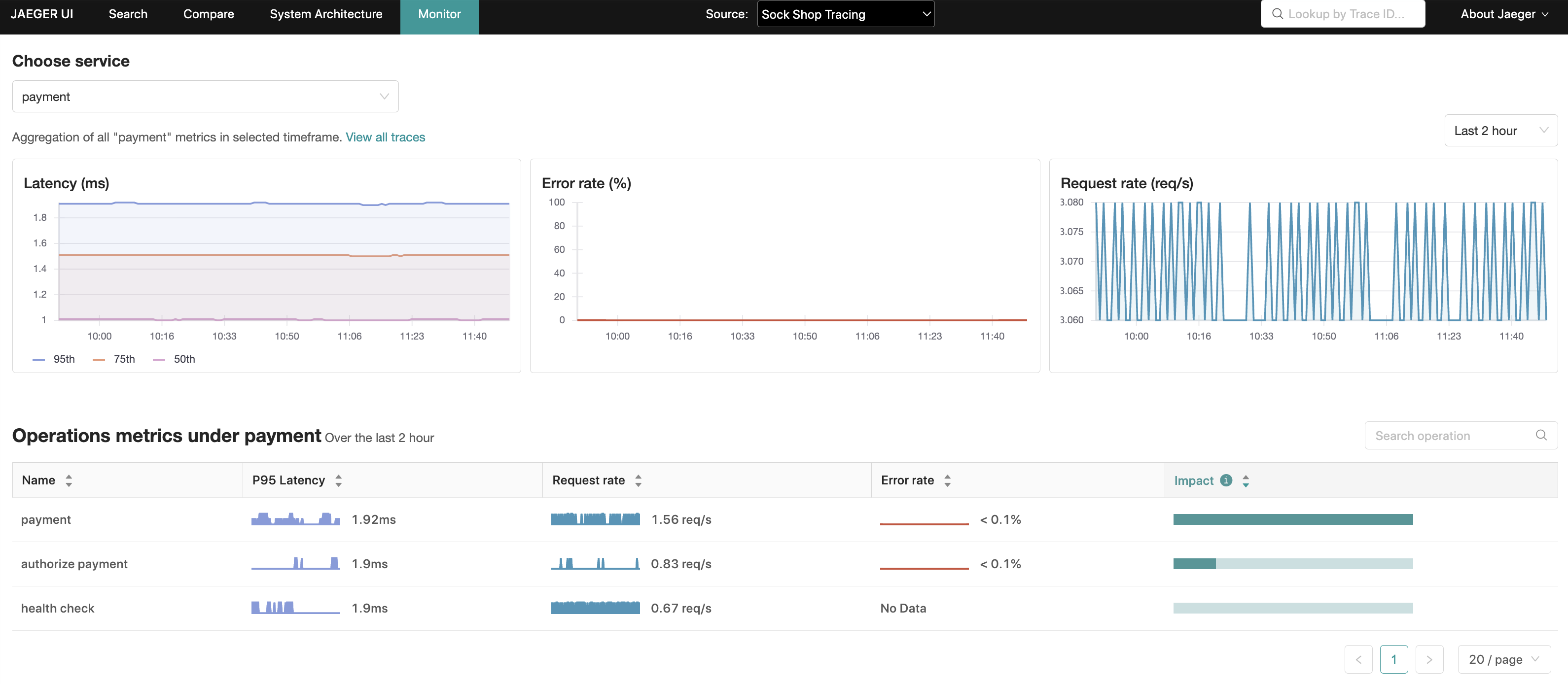
此功能在 Jaeger UI 中以“监控”选项卡的形式呈现,其目的是帮助识别有趣的追踪(例如高 QPS、慢速或错误请求),而无需预先知道服务或操作名称。
它主要通过聚合 span 数据来生成 RED (请求、错误、持续时间) 指标。
潜在用例包括
- 在整个组织或请求链中已知的依赖服务上进行部署后的健全性检查。
- 在收到警报时进行监控和根因分析。
- 为 Jaeger UI 的新用户提供更好的入门体验。
- QPS、错误和延迟的长期趋势分析。
- 容量规划。
UI 功能概述
“监控”选项卡提供服务级别的聚合,以及服务内部操作级别的请求率、错误率和持续时间(P95、P75 和 P50)聚合,也称为 RED 指标。
在操作级别聚合中,还有一个“影响”指标,它被计算为延迟和请求率的乘积,这是另一个可用于排除可能自然具有高延迟特性(例如每日批处理作业)的操作的信号,反之亦可突出显示延迟排名较低但 RPS(每秒请求数)较高的操作。
通过这些聚合,Jaeger UI 能够使用相关的服务、操作和回溯周期预填充追踪搜索,从而缩小这些更有趣追踪的搜索范围。
入门
Jaeger 仓库 中提供了一个本地可运行的设置,以及如何运行它的说明。
该功能可从顶部菜单的“监控”选项卡访问。
此演示包括 Microsim ;一个微服务模拟器,用于生成追踪数据。
如果 prefer 手动生成追踪,则可以通过 docker 启动示例应用程序:HotROD。请务必在docker run命令中包含--net monitor_backend。
配置
Jaeger 仓库中提供了一个示例配置:config-spm.yaml 。启用 SPM 功能需要以下步骤
- 在管道中启用 SpanMetrics 连接器
# Declare an exporter for metrics produced by the connector.
# For example, a Prometheus server may be configured to scrape
# the metrics from this endpoint.
exporters:
prometheus:
endpoint: "0.0.0.0:8889"
# Declare spanmetrics connector.
connectors:
spanmetrics:
# any connector configuration options
...
# Enable the spanmetrics connector to bridge
# the traces pipeline into the metrics pipeline.
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [jaeger_storage_exporter, spanmetrics]
metrics/spanmetrics:
receivers: [spanmetrics]
exporters: [prometheus]
- 在
jaeger_storage扩展下的metric_backends:中定义一个远程 PromQL 兼容的存储
extensions:
jaeger_storage:
backends:
some_trace_storage:
...
metric_backends:
some_metrics_storage:
prometheus:
endpoint: http://prometheus:9090
- 在
jaeger_query扩展中引用此指标存储
extensions:
jaeger_query:
traces: some_trace_storage
metrics_storage: some_metrics_storage
- 在 Jaeger UI 配置中设置
monitor.menuEnabled=true属性。
架构
除了标准的 Jaeger 架构外,SPM 功能还需要以下附加组件
- 在接收追踪数据 (spans) 并生成 RED 指标的管道中引入了 SpanMetrics 连接器 。
- 生成的指标被导出到兼容 Prometheus 的指标存储。在提供的示例中,这是通过定义一个打开 HTTP 端点的
prometheus导出器,并配置 Prometheus 服务器从该端点抓取指标来实现的。另一种方法是采用推送式导出器,将数据写入远程指标存储。 - 一个支持 PromQL 查询的外部指标存储。
jaeger_query扩展中的一个配置,用于引用外部指标存储。
指标存储
Jaeger Query 支持任何兼容 PromQL 的后端。Julius Volz 在以下文章中整理了这些后端列表:https://promlabs.com/blog/2020/11/26/an-update-on-promql-compatibility-across-vendors
派生时间序列
了解 SpanMetrics 连接器 在指标存储中生成的附加指标和时间序列对于部署 SPM 时的容量规划非常重要。
请参阅 Prometheus 文档 ,其中涵盖了指标名称、类型、标签和时间序列的概念;这些术语将在本节的其余部分中使用。
将创建两个指标名称
calls_total- 类型:计数器
- 描述:统计 span 的总数,包括错误 span。调用计数与错误通过
status_code标签区分。任何带有标签status_code = "STATUS_CODE_ERROR"的时间序列都被标识为错误。
[命名空间_]duration_[单位]- 类型:直方图
- 描述:span 持续时间/延迟的直方图。在底层,Prometheus 直方图会创建多个时间序列。为了便于说明,假设未配置命名空间,并且单位是
milliseconds。duration_milliseconds_count:直方图中所有桶中数据点的总数。duration_milliseconds_sum:所有数据点值的总和。duration_milliseconds_bucket:针对每个持续时间桶(由le(小于或等于) 标签标识)的一系列n个时间序列(其中n是持续时间桶的数量)。对于每个 span,具有最低le且le >= span duration的duration_milliseconds_bucket计数器将增加。
以下公式旨在提供有关新创建时间序列数量的一些指导
num_status_codes * num_span_kinds * (1 + num_latency_buckets) * num_operations
Where:
num_status_codes = 3 max (typically 2: ok/error)
num_span_kinds = 6 max (typically 2: client/server)
num_latency_buckets = 17 default
代入这些数字,假设默认配置
max = 324 * num_operations
typical = 72 * num_operations
注意
API
gRPC/Protobuf
以编程方式检索 RED 指标的推荐方式是通过 metricsquery.proto IDL 文件中定义的 jaeger.api_v2.metrics.MetricsQueryService gRPC 端点。
HTTP JSON
由 Jaeger UI 的监控选项卡内部使用,用于填充其可视化指标。
有关 HTTP API 的详细规范,请参阅此 README 文件 。
故障排除
检查 Jaeger-Prometheus 连接
通过检查 Jaeger 内部遥测数据,验证 Jaeger 查询* 是否可以连接到 Prometheus 兼容的指标存储。
Jaeger 配置需要在 telemetry: 部分启用一个指标端点。请注意,内部遥测应该暴露在与用于从 spanmetrics 连接器导出指标的端口(例如 8889)不同的端口(例如 8888)上。
service:
...
telemetry:
resource:
service.name: jaeger
metrics:
level: detailed
address: 0.0.0.0:8888
此端口上的 /metrics 端点可用于检查 SPM 数据 UI 查询是否成功
curl -s http://jaeger:8888/metrics | grep jaeger_metricstore
以下指标最值得关注
jaeger_metricstore_requests_totaljaeger_metricstore_latency_bucket
这些指标中的每一个都将为以下每个操作提供一个标签
get_call_ratesget_error_ratesget_latenciesget_min_step_duration
如果一切按预期工作,带有 result="ok" 标签的指标应该递增,而 result="err" 保持不变。例如
jaeger_metricstore_requests_total{operation="get_call_rates",result="ok"} 18
jaeger_metricstore_requests_total{operation="get_error_rates",result="ok"} 18
jaeger_metricstore_requests_total{operation="get_latencies",result="ok"} 36
jaeger_metricstore_latency_bucket{operation="get_call_rates",result="ok",le="0.005"} 5
jaeger_metricstore_latency_bucket{operation="get_call_rates",result="ok",le="0.01"} 13
jaeger_metricstore_latency_bucket{operation="get_call_rates",result="ok",le="0.025"} 18
jaeger_metricstore_latency_bucket{operation="get_error_rates",result="ok",le="0.005"} 7
jaeger_metricstore_latency_bucket{operation="get_error_rates",result="ok",le="0.01"} 13
jaeger_metricstore_latency_bucket{operation="get_error_rates",result="ok",le="0.025"} 18
jaeger_metricstore_latency_bucket{operation="get_latencies",result="ok",le="0.005"} 7
jaeger_metricstore_latency_bucket{operation="get_latencies",result="ok",le="0.01"} 25
jaeger_metricstore_latency_bucket{operation="get_latencies",result="ok",le="0.025"} 36
如果从 Prometheus 读取指标时出现问题,例如无法连接到 Prometheus 服务器,那么 result="err" 指标将会递增。例如
jaeger_metricstore_requests_total{operation="get_call_rates",result="err"} 4
jaeger_metricstore_requests_total{operation="get_error_rates",result="err"} 4
jaeger_metricstore_requests_total{operation="get_latencies",result="err"} 8
此时,检查日志将提供更多关于问题根本原因的见解。
查询 Prometheus
即使上述 Jaeger 指标显示从 Prometheus 读取成功,图表仍可能显示为空。在这种情况下,请直接查询 Prometheus 中应该由 spanmetrics 连接器生成的任何指标:
traces_span_metrics_duration_milliseconds_buckettraces_span_metrics_calls_total
随着 Jaeger 收到追踪,您应该会看到这些计数器持续增加。
检查日志
如果上述指标存在于 Prometheus 中,但未出现在“监控”选项卡中,则表示 Jaeger 期望在 Prometheus 中看到的指标与实际可用的指标之间存在差异。
这可以通过增加日志级别来确认
service:
telemetry:
...
logs:
level: debug
输出类似于以下内容的日志(为便于阅读已格式化)
2024-11-26T19:09:43.152Z debug metricsstore/reader.go:258 Prometheus query results
{
"kind": "extension",
"name": "jaeger_storage",
"results": "",
"query": "sum(rate(traces_span_metrics_calls_total{service_name =~ \"redis\", span_kind =~ \"SPAN_KIND_SERVER\"}[10m])) by (service_name,span_name)",
"range": {
"Start": "2024-11-26T19:04:43.14Z",
"End": "2024-11-26T19:09:43.14Z",
"Step": 60000000000
}
}
在此示例中,假设 OpenTelemetry Collector 的 prometheusexporter 引入了一项破坏性更改,它会在计数器指标和直方图指标中的持续时间单位(例如 duration_milliseconds_bucket)后附加 _total 后缀。正如我们发现的,Jaeger 正在寻找 calls(和 duration_bucket)指标名称,而 OpenTelemetry Collector 正在写入 calls_total(和 duration_milliseconds_bucket)。
在这种特定情况下,解决方案是向指标后端配置传递参数,告诉 Jaeger 规范化指标名称,以便它知道转而搜索 calls_total 和 duration_milliseconds_bucket,如下所示
extensions:
jaeger_storage:
backends:
...
metric_backends:
some_metrics_storage:
prometheus:
endpoint: http://prometheus:9090
normalize_calls: true
normalize_duration: true
检查 OpenTelemetry Collector 配置
如果 Jaeger 中出现错误 span,但没有相应的错误指标
- 检查 Prometheus 中由 spanmetrics 连接器生成的原始指标(如上所列:
calls、calls_total、duration_bucket等)是否包含 span 所属指标中的status.code标签。 - 如果不存在
status.code标签,请检查 OpenTelemetry Collector 配置文件,特别是是否存在以下配置:Jaeger 使用此标签来确定请求是否出错。exclude_dimensions: ['status.code']
检查 OpenTelemetry Collector
如果上述 latency_bucket 和 calls_total 指标为空,则可能是 OpenTelemetry Collector 或其上游的任何组件配置错误。
故障排除时要问的一些问题是
- OpenTelemetry Collector 配置是否正确?
- Prometheus 服务器是否可以被 OpenTelemetry Collector 访问?
- 服务是否正在向 OpenTelemetry Collector 发送 span?
监控选项卡中缺少服务/操作
如果“监控”选项卡中缺少服务/操作,但在 Jaeger 追踪搜索服务和操作下拉菜单中可见,则常见原因是指标查询中使用的默认 server span 类型。
您未看到的服务/操作可能来自非服务器 span 类型(例如客户端或更糟的 unspecified)的 span。因此,这是一个仪表数据质量问题,仪表应设置 span 类型。
默认为 server span 类型的原因是为了避免在 server 和 client span 类型中分别重复计算入口和出口 span。
执行指标查询时出现 403 错误
如果日志包含类似于 failed executing metrics query: client_error: client error: 403 的错误,则 Prometheus 服务器可能需要一个 bearer token。
Jaeger 可以配置为在指标查询中传递 bearer token。token 可以通过 token_file_path: 属性定义
extensions:
jaeger_storage:
backends:
...
metric_backends:
some_metrics_storage:
prometheus:
endpoint: http://prometheus:9090
token_file_path: /path/to/token/file
token_override_from_context: true
