 我们与乌克兰的朋友和同事们同在。如需支持乌克兰度过难关,请
我们与乌克兰的朋友和同事们同在。如需支持乌克兰度过难关,请服务性能监控 (SPM)
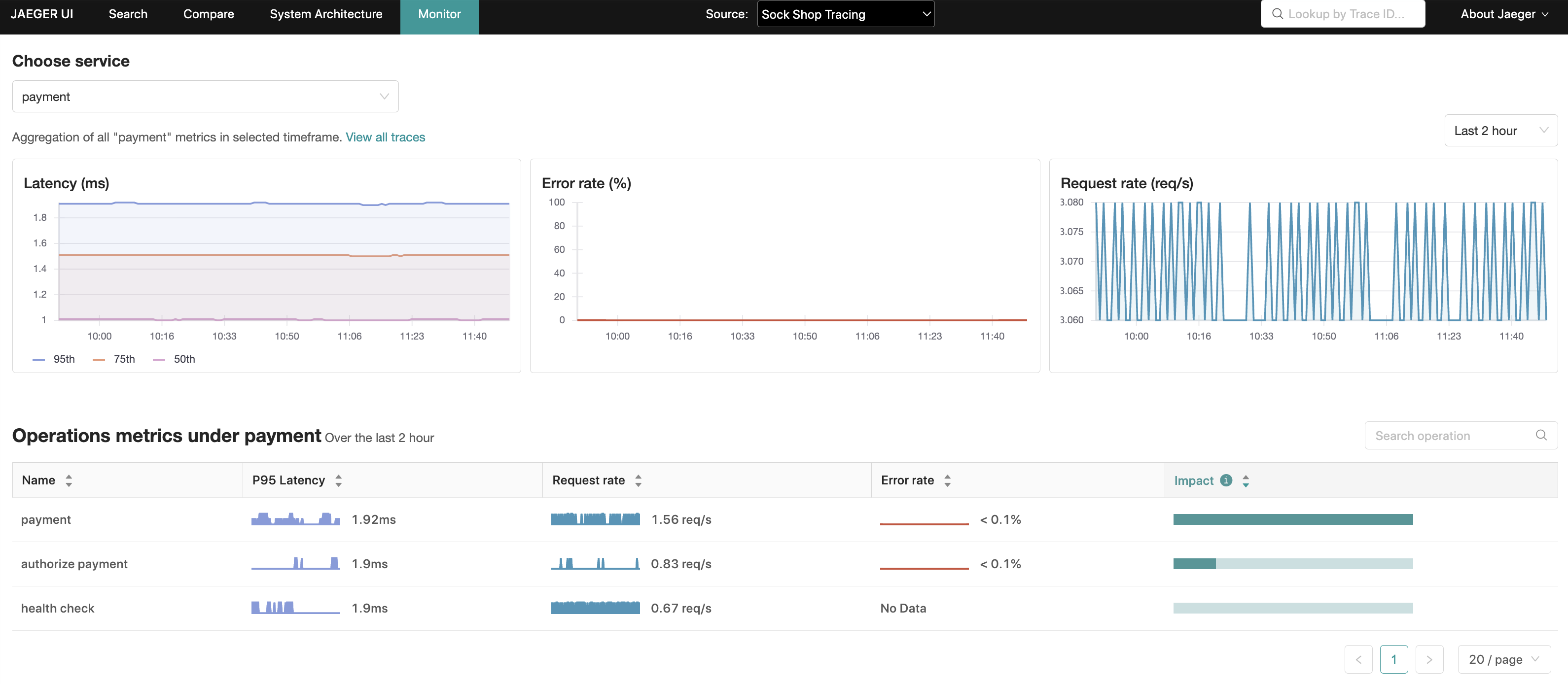
Jaeger UI 中以“监控”选项卡的形式呈现,此功能的目的是帮助识别有趣的追踪(例如高 QPS、慢速或错误请求),而无需预先知道服务或操作名称。
它主要通过聚合 span 数据来生成 RED(请求、错误、持续时间)指标来实现。
潜在用例包括
- 在整个组织范围内或在请求链中已知依赖的服务上进行部署后的健康检查。
- 在收到警报时进行监控和根因分析。
- 为 Jaeger UI 的新用户提供更好的入门体验。
- QPS、错误和延迟的长期趋势分析。
- 容量规划。
UI 功能概述
“监控”选项卡提供了服务级别的聚合,以及服务内部操作级别的聚合,包括请求率、错误率和持续时间(P95、P75 和 P50),这些也称为 RED 指标。
在操作级别的聚合中,一个“影响”指标(计算为延迟与请求率的乘积)是另一个信号,可用于排除可能自然具有高延迟特征的操作(例如每日批处理作业),或反过来突出显示在延迟排名中较低但 RPS(每秒请求数)较高的操作。
通过这些聚合,Jaeger UI 能够使用相关的服务、操作和回溯周期预填充追踪搜索,从而缩小这些更有趣追踪的搜索范围。
入门
Jaeger 仓库中提供了一个可在本地运行的设置,以及如何运行它的说明。Jaeger 仓库
该功能可以通过顶部菜单中的“监控”选项卡访问。
此演示包括 Microsim ;一个用于生成追踪数据的微服务模拟器。
如果偏好手动生成追踪,可以通过 Docker 启动示例应用:HotROD。请务必在 `docker run` 命令中包含 `--net monitor_backend`。
架构
Jaeger 为“监控”选项卡查询的 RED 指标是 OpenTelemetry 收集器 收集的 span 数据的结果,这些数据随后由其管道中配置的 SpanMetrics 连接器 组件进行聚合。
这些指标最终由 OpenTelemetry 收集器(通过 Prometheus 导出器)导出到兼容 Prometheus 的指标存储。
需要强调的是,这是一个“只读”功能,因此仅与 Jaeger 查询组件(以及 All In One)相关。
派生时间序列
尽管这更属于 OpenTelemetry 收集器 的范围,但了解 SpanMetrics 连接器 将在指标存储中生成的额外指标和时间序列有助于在部署 SPM 时进行容量规划。
请参阅 Prometheus 文档 ,其中涵盖了指标名称、类型、标签和时间序列的概念;这些术语将在本节的其余部分中使用。
将创建两个指标名称
calls_total- 类型:计数器
- 描述:计算 span 的总数,包括错误 span。调用计数通过 `status_code` 标签与错误区分开。错误被识别为任何带有标签 `status_code = "STATUS_CODE_ERROR"` 的时间序列。
[命名空间_]duration_[单位]- 类型:直方图
- 描述:span 持续时间/延迟的直方图。在底层,Prometheus 直方图将创建多个时间序列。为便于说明,假设未配置命名空间,并且单位为毫秒。
- `duration_milliseconds_count`:直方图中所有桶的数据点总数。
- `duration_milliseconds_sum`:所有数据点值的总和。
- `duration_milliseconds_bucket`:每个持续时间桶的时间序列集合(其中 `n` 是持续时间桶的数量),通过 `le`(小于或等于)标签标识。每个 span 将使具有最低 `le` 且 `le >= span duration` 的 `duration_milliseconds_bucket` 计数器递增。
以下公式旨在为新创建的时间序列数量提供一些指导
num_status_codes * num_span_kinds * (1 + num_latency_buckets) * num_operations
Where:
num_status_codes = 3 max (typically 2: ok/error)
num_span_kinds = 6 max (typically 2: client/server)
num_latency_buckets = 17 default
代入这些数字,假设默认配置
max = 324 * num_operations
typical = 72 * num_operations
注意
配置
启用 SPM
启用 SPM 功能需要以下配置
- Jaeger UI
- Jaeger 查询
- 将 `METRICS_STORAGE_TYPE` 环境变量设置为 `prometheus`。
- 可选:将 `--prometheus.server-url`(或 `PROMETHEUS_SERVER_URL` 环境变量)设置为 Prometheus 服务器的 URL。默认值:https://:9090。
API
gRPC/Protobuf
以编程方式检索 RED 指标的推荐方法是通过 metricsquery.proto IDL 文件中定义的 `jaeger.api_v2.metrics.MetricsQueryService` gRPC 端点。
HTTP JSON
Jaeger UI 的“监控”选项卡内部使用,用于为其可视化填充指标。
有关 HTTP API 的详细规范,请参阅此 README 文件 。
故障排除
检查 /metrics 端点
`/metrics` 端点可用于检查是否接收到特定服务的 span。`/metrics` 端点通过管理端口提供服务。假设 Jaeger all-in-one 和 query 分别在名为 `all-in-one` 和 `jaeger-query` 的主机下可用,以下是获取指标的示例 `curl` 调用
$ curl http://all-in-one:14269/metrics
$ curl http://jaeger-query:16687/metrics
以下指标最值得关注
# all-in-one
jaeger_requests_total
jaeger_latency_bucket
# jaeger-query
jaeger_query_requests_total
jaeger_query_latency_bucket
这些指标中的每一个都将包含以下每个操作的标签
get_call_rates
get_error_rates
get_latencies
get_min_step_duration
如果一切按预期工作,带有标签 `result="ok"` 的指标应该会递增,而 `result="err"` 则保持不变。例如
jaeger_query_requests_total{operation="get_call_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_error_rates",result="ok"} 18
jaeger_query_requests_total{operation="get_latencies",result="ok"} 36
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.005"} 5
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_call_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.01"} 13
jaeger_query_latency_bucket{operation="get_error_rates",result="ok",le="0.025"} 18
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.005"} 7
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.01"} 25
jaeger_query_latency_bucket{operation="get_latencies",result="ok",le="0.025"} 36
如果从 Prometheus 读取指标时出现问题,例如无法连接到 Prometheus 服务器,则 `result="err"` 指标将会递增。例如
jaeger_query_requests_total{operation="get_call_rates",result="err"} 4
jaeger_query_requests_total{operation="get_error_rates",result="err"} 4
jaeger_query_requests_total{operation="get_latencies",result="err"} 8
此时,检查日志将提供更多关于问题根本原因的见解。
查询 Prometheus
即使上述 Jaeger 指标表明成功从 Prometheus 读取数据,图表仍可能显示为空。在这种情况下,请直接在 Prometheus 上查询以下任一指标
duration_bucketduration_milliseconds_bucketduration_seconds_bucketcallscalls_total
您应该会看到这些计数器随着服务向 OpenTelemetry 收集器发出 span 而递增。
查看日志
如果上述指标存在于 Prometheus 中,但未出现在“监控”选项卡中,则表示 Jaeger 期望在 Prometheus 中看到的指标与实际可用的指标之间存在差异。
通过设置以下环境变量来增加日志级别,可以确认这一点
LOG_LEVEL=debug
输出类似以下内容的日志
{
"level": "debug",
"ts": 1688042343.4464543,
"caller": "metricsstore/reader.go:245",
"msg": "Prometheus query results",
"results": "",
"query": "sum(rate(calls{service_name =~ \"driver\", span_kind =~ \"SPAN_KIND_SERVER\"}[10m])) by (service_name,span_name)",
"range":
{
"Start": "2023-06-29T12:34:03.081Z",
"End": "2023-06-29T12:39:03.081Z",
"Step": 60000000000
}
}
在此示例中,假设 OpenTelemetry 收集器的 `prometheusexporter` 引入了一个重大变更,它将 `_total` 后缀附加到计数器指标和直方图指标中的持续时间单位(例如 `duration_milliseconds_bucket`)。正如我们所发现的,Jaeger 正在查找 `calls`(和 `duration_bucket`)指标名称,而 OpenTelemetry 收集器正在写入 `calls_total`(和 `duration_milliseconds_bucket`)。
在这种特定情况下,解决方案是设置环境变量,告诉 Jaeger 规范化指标名称,使其知道转而搜索 `calls_total` 和 `duration_milliseconds_bucket`,如下所示
PROMETHEUS_QUERY_NORMALIZE_CALLS=true
PROMETHEUS_QUERY_NORMALIZE_DURATION=true
检查 OpenTelemetry Collector 配置
如果在 Jaeger 中出现错误 span,但没有相应的错误指标
- 检查由 spanmetrics 连接器在 Prometheus 中生成的原始指标(如上所述:`calls`、`calls_total`、`duration_bucket` 等)是否包含 span 所属指标中的 `status.code` 标签。
- 如果没有 `status.code` 标签,请检查 OpenTelemetry 收集器配置文件,特别是是否存在以下配置Jaeger 使用此标签来确定请求是否包含错误。
exclude_dimensions: ['status.code']
检查 OpenTelemetry Collector
如果上述 `latency_bucket` 和 `calls_total` 指标为空,则可能是 OpenTelemetry 收集器或其上游的配置错误。
故障排除时要问的一些问题是
- OpenTelemetry Collector 配置是否正确?
- Prometheus 服务器是否可以被 OpenTelemetry 收集器访问?
- 服务是否正在向 OpenTelemetry Collector 发送 span?
监控选项卡中缺少服务/操作
如果服务/操作在“监控”选项卡中缺失,但在 Jaeger 追踪搜索的服务和操作下拉菜单中可见,常见原因是指标查询中使用了默认的 `server` span 类型。
您未看到的服务/操作可能来自非 `server` span 类型(例如 `client` 或更糟糕的 `unspecified`)的 span。因此,这是一个仪表化数据质量问题,仪表化应该设置 span 类型。
默认使用 `server` span 类型的原因是为了避免分别在 `server` 和 `client` span 类型中重复计算入口和出口 span。
执行指标查询时出现 403 错误
如果日志包含类似:`failed executing metrics query: client_error: client error: 403` 的错误,则可能是 Prometheus 服务器正在等待一个持有者令牌。
Jaeger Query(和 all-in-one)可以通过 `--prometheus.token-file` 命令行参数(或 `PROMETHEUS_TOKEN_FILE` 环境变量)配置在指标查询中传递持有者令牌,其值设置为包含持有者令牌的文件的路径。
